

《投资管理》/ China JOIM第11期——AI for Investment Ⅱ(锁定AI落地最后一公里:从实证到实践_2025_新闻动态_衡泰技术-领先的金融行业定量分析与技术供应商点击回顾),也是AI专刊第二楫的“中国实践”栏目中,广发证券副总经理、首席信息官辛治运,以及王蓁、苗园莉三位专家,撰文分享对AI应用探索的深度思考。
文章超越纯技术视角,探讨并展望大模型浪潮如何从技术实践、范式演进到生态重构层面,重塑金融行业组织架构与资源文化。
作为系列文章的第一篇,本文中对生成式搜索引擎优化(GEO,Generative Engine Optimization)的深度思考和细节探索,更为行业突破传统思维局限提供了有益尝试。
作者 :辛治运b,*、王蓁a,*、苗园莉*
a第一作者,b通讯作者,*广发证券
引言
过去十数年人工智能技术在金融行业的广泛使用,伴随着金融科技行业的兴起,似乎体现了技术落地的 “马尔萨斯陷阱”¹。
当前,大模型如火如荼,金融行业AI应用正从 “由薄做厚”的场景积累期,向 “由厚做薄” 的价值萃取期跃迁,短期目标做精品高价值标杆应用,中长期希望实现对业务模式和客户服务模式的重构。
这一次大模型引领的智能化浪潮,是马尔萨斯1800年前短暂的均值偏离,还是突破陷阱的第一次工业革命,金融机构和从业者如何在工具爆炸式迭代中锚定真正改变行业生产关系的核心范式?
金融机构的AI转型从来不只是技术问题。本系列将沿着“技术实践—范式演进—生态重构”的脉络,揭示AI如何从流量转化、智能研发等效率工具进化为对金融行业组织架构和资源文化的冲击,为机构破解创新焦虑提供另一种视角和思考展望。
¹“马尔萨斯陷阱”(Malthusian Trap),由英国经济学家托马斯・罗伯特・马尔萨斯(Thomas Robert Malthus)在1798年出版的《人口原理》中提出,核心观点是:当人口增长超过社会资源(如粮食)的承载能力时,会通过饥荒、战争、疾病等“积极抑制”手段迫使人口回归平衡,形成“人口增长—资源短缺—人口减少”的循环。
问题一:
如何让DeepSeek/豆包等在回答里推荐你的公司?
我们希望不管是个人用户还是企业客户,在使用DeepSeek、豆包等生成式搜索引擎查询相关内容时,能够清晰且优先获取到机构自身的优势信息,例如 “产品性价比高”、“服务贴心”等 ;如果涉及证券业务搜索,能优先看到对特定机构的推荐。
生成式搜索引擎优化(GEO,Generative Engine Optimization)应运而生。GEO是一种旨在通过优化策略,使特定内容在豆包、DeepSeek等生成式搜索引擎的答复结果中,得以清晰且优先展示的技术与方法体系。
我们的核心目标就是确保用户在搜索相关信息时,能便捷地获取到对我们业务发展和品牌建设具有积极推动作用的有效信息。
01
生成式搜索引擎的工作原理
我们梳理了生成式搜索引擎的工作原理(图1),关键环节包括大模型记忆知识、搜索引擎联网检索和大模型总结答复三大部分:
大模型记忆知识
在大模型记忆知识阶段,大模型通过对海量文本数据的学习与存储,构建起知识体系,并将信息以参数形式记忆下来,用于后续分析用户提问。这一过程就如同大脑不断吸收知识,形成储备库以便快速检索调用。
此阶段的关键是,通过大量不重复且高质量的PR稿(新闻通稿、品牌传播文案等)引导大模型学习与企业、产品或服务相关的核心优势信息,确保这些关键内容被深度记忆,便于后续能被高效检索,为用户查询提供有力支撑。
搜索引擎联网检索
当大模型无法满足复杂、实时的提问需求时,搜索引擎便会启动联网功能,依据关键词在互联网中筛选、抓取网页信息,并反馈给大模型,这就是搜索引擎联网检索阶段。该阶段类似于撰稿人基于文章主题在互联网中搜集最新、相关的素材。
此阶段的关键在于针对特定的业务搜索需求,精准设置SEO策略,让搜索引擎能优先抓取对业务发展和品牌建设有积极推动作用的信息,为后续的答复提供优质素材。此阶段取决于不同模型的具体搜索策略,与传统搜索引擎不一致。
大模型总结答复
最后是大模型总结答复阶段,该阶段大模型会整合记忆中的知识以及检索到的信息生成用户答复,这如同撰稿人梳理、组织素材创作出高质量文章。
此阶段的关键在于运用一系列PR稿内容优化策略,如嵌入特定关键词、合理调整语句用词方式等,使大模型在总结答复时,能够将企业希望用户优先获取的优势信息,以自然流畅的方式呈现。
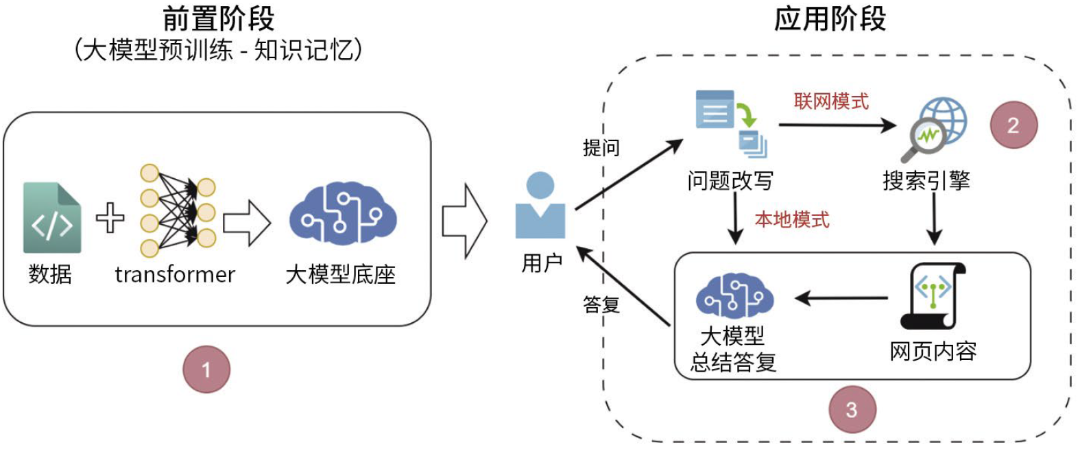
图1 生成式搜索引擎工作原理
因此,若要提升特定知识在生成式搜索引擎中的曝光率,可从以下三个维度加以考量:
优化特定知识在LLM参数知识中的存储容量;
优化网页在搜索引擎的搜索排名;
针对 LLM 处理信息时的特性进行优化,优化LLM答案生成过程。
02
生成式搜索引擎的优化阶段划分与产品分析
(一)GEO三阶段划分
针对生成式搜索引擎的三个工作阶段,即LLM本地答复、通过搜索引擎联网召回网页数据和通过LLM生成问题答案,我们总结了GEO的三个阶段,按照生成式搜索引擎工作流程的时间顺序,划分为LLM参数知识容量优化、搜索引擎联网召回优化,以及LLM总结答复过程优化。
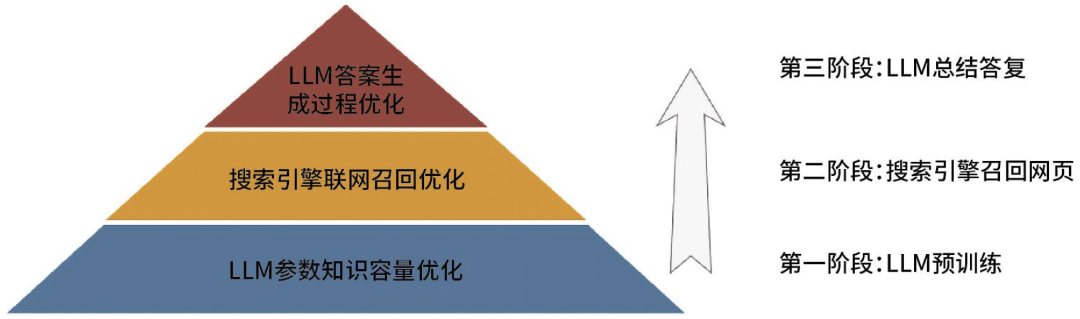
图2 生成式搜索引擎关键流程和对应GEO三阶段优化划分
(二)主流生成式搜索引擎分析
基于生成式搜索引擎的工作流程,下面对四个主流的生成式搜索引擎进行了对比分析,分析对象包括豆包、Kimi、DeepSeek和腾讯元宝。通过对比不同生成式搜索引擎的对话界面和引用网页的标注特点,我们推断了不同引擎在第三阶段的工作流程。
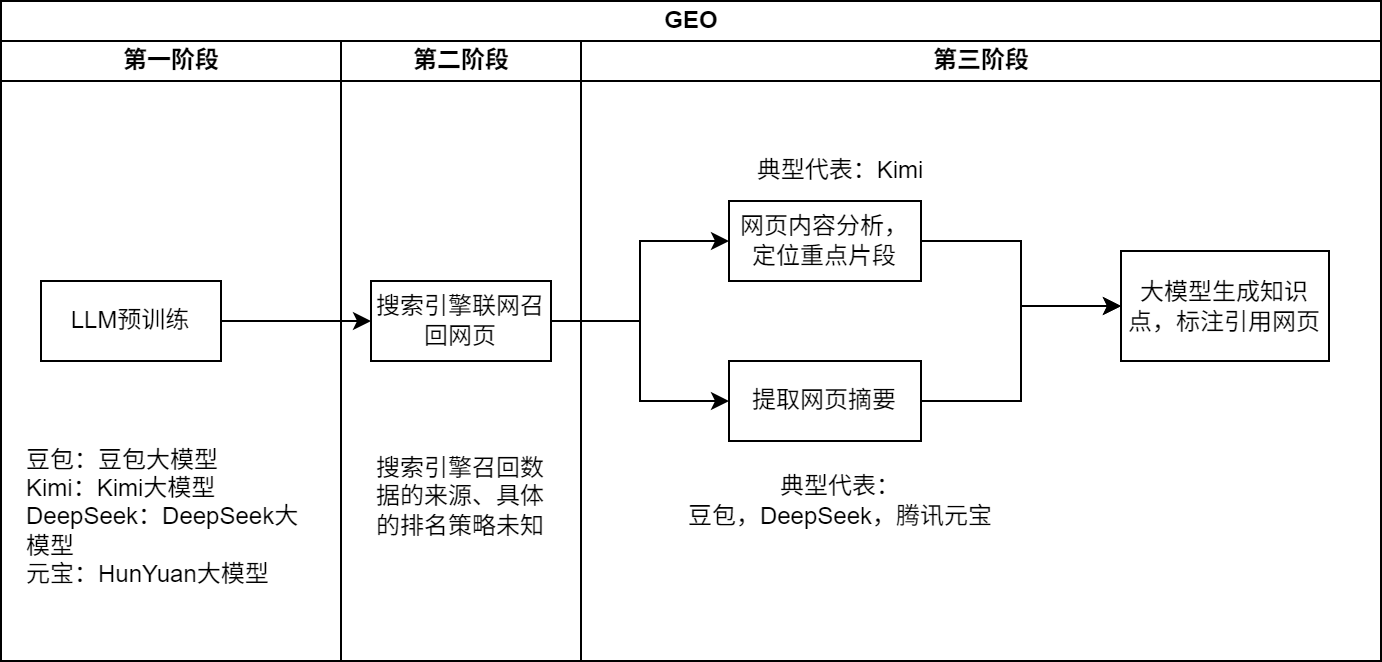
图3 国内主流生成式搜索引擎分析(示例)
03
GEO各阶段的操作目标分析与实操建议
(一)优化LLM参数知识存储容量
优化参数知识存储容量,该阶段一般发生在大模型预训练或者微调阶段,关键是通过提升特定知识在大模型训练数据中出现的频率,实现提升该知识在大模型参数知识中的存储容量,从而提升该知识在大模型输出中出现的频率。除此之外,添加特殊标记(类似域名)到特定数据前,能让模型自动识别并优先学习这些数据,从而提升对应的知识容量。
为了大模型能记住更多关于目标宣传公司的正面信息,公司需要发布大量高质量、不重复的 PR 稿,增加公司正面信息在大模型预训练语料中的出现频率。
(二)优化搜索引擎联网搜索排名
为了准确回复用户问题,生成式搜索引擎会通过传统搜索引擎联网去获取与用户提问相关的各种网页数据,作为LLM生成回复答案的参考依据。对于联网搜索的场景,特定知识所在网页需要被搜索引擎召回,才能作为答案出现在LLM的输出中。如何提升网页排名(传统SEO)是该阶段的关键。
核心还是网页数据在搜索引擎的排名和曝光,决定了最后大模型在此环节回答的推进。为了让目标宣传公司的网页被搜索引擎召回,我们需要加强传统的SEO策略,增加公司网页在搜索引擎召回结果中的排名。
(三)优化LLM总结答复过程
在大模型总结答复过程中,会先通过大模型或者其它AI模型对召回的原始网页内容进行预处理,包括识别网页中关键文本片段或者提取网页摘要,然后将预处理的内容作为上下文给大模型参考,大模型基于此上下文进行知识点总结输出。
在这一阶段,我们既要让目标宣传公司相关的正面信息出现在网页内容预处理结果中,也要让大模型在总结知识点时关注到并输出公司相关的内容。这一步的关键,就是通过添加专业术语、权威术语、统计数据等手段进行PR稿优化,让大模型重点关注到公司相关内容。
(四)通用GEO策略建议总结

图4 通用GEO策略建议
结合传统SEO策略及论文研究提出的9种GEO优化策略,我们整理了11种通用GEO策略,并按照位置调整词数(Position-Adjusted Word Count)和主观印象分(Subjective Impression)两个GEO评估指标(评估指标的详细解释见附录1),将策略按照性能提升幅度从高到低进行排序。位置调整词数综合考虑生成引擎响应中引用的词频和引用位置,主观印象分通过计算多个主观因素得出整体印象评分。
表1 部分GEO优化策略
(PAWC和SI两个指标的定义参见附录1)

数据来源:Aggarwal P, Murahari V, Rajpurohit T, et al. GEO: Generative Engine Optimization[C]//Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
04
问题的延伸:从 GEO 到搜推一体化:金融机构流量转化的 “最后一公里”困局
在生成式搜索引擎优化(GEO)解决 “信息可见性”之后,金融机构正面临更复杂的命题:如何将被动的信息曝光转化为主动的业务增长?这需要从单一的 “信息展示思维” 转向 “流量运营生态”,将用户搜索行为从 “获取信息”转向 “投资决策”,将新生态流量转化为真实的业务价值,这是金融行业在 AI 时代必须破解的 “场景适配性” 命题。
在金融行业,合规性与体验性的对立、需求复杂性与技术通用性的矛盾等,尤为突出。这种困境的根源,时序维度来看,在于金融机构将搜推视为 “技术工具”而非 “用户洞察入口”。当互联网平台通过搜推构建 “需求—供给”的实时转化漏斗时,大多数金融机构仍停留在 “关键词匹配 + 合规模板” 的初级阶段,谨慎下没有充分有效利用这部分流量。
横向维度来看,这也是 “标准化技术”与 “非标化需求” 的冲突:大厂成熟的 “搜索 - 推荐 - 转化” 闭环(如电商平台基于浏览历史的动态推荐),在金融场景中可能因触及监管红线而失灵。如果简单照搬互联网 “猜你喜欢”模式,而未充分考虑合规风控规则,可能东施效颦,导致高风险产品误推给保守型客户等合规风险。
AI 的价值正在于解构金融需求的复杂性,在于将金融需求解构为可计算的 “意图网络”。这里面包括对监管外规内规的意图理解、对用户的动态画像、对上下文场景的意图理解、以及搜推一体的转化钩子设计。借鉴 LLM 从 RLHF(基于人类反馈的强化学习)到 RRM(Reinforcement Learning based on Real-time Market Feedback,基于实时市场反馈的强化学习)的进化路径,我们认为,未来的金融搜推系统可能会朝着 “数据闭环—策略迭代—体验升级” 的正向循环逐步演进。
这种从 “被动响应” 到 “主动预判”的跃迁,未尝不是金融服务从 “产品中心” 向 “客户中心”转变的范式革命。当 GEO 逐步实现 “让机构被看见”的数据积累,搜推一体化是紧随其后的“让服务被需要”的价值转化新规则。这是AI的泛化外延,更是对金融本质 “理解客户、服务客户” 的回归。
问题二:
LLM对社会的重构:从微观到宏观
01
第一层,对金融机构的冲击
在 LLM 驱动的智能革命中,以细分场景为壁垒的中小金融机构正面临生存压力。当大模型能低成本实现全品类金融服务的智能化覆盖,依赖区域资源或垂直客群的 “小而美”模式逐渐失效,细分特色金融业务的价值会下降。
金融机构组织架构层面,传统 “分灶吃饭、财政包干” 的分散式管理体系,在需要数据共享与算法协同的 AI 时代暴露出天然短板:独立业务单元的重复建设导致资源内耗,而决策权限的过度分散抑制了技术规模化应用的可能。
对于单一金融机构而言,“分税制改革” 式的统筹式调整成为必然选择:通过加强中央财力,建立公司级的 AI 中台整合算力、数据与模型资源,在 “总部统筹”与 “地方灵活性”之间重构权力均衡。当业务流程被算法重新定义,组织内部的 “央地博弈” 将从资源分配转向能力协同,机构在“统收统支”与“地方创新”之间的终会达到新的央地平衡。
判断:互联网公司会比金融机构在AI方面进化更快
不谈数据、监管、资金投入等,只考虑一个角度,当前较好的AI产品,通常团队自己就是产品的用户,互联网天然有这个优势,而金融机构缺乏,从业者监管原因和准入资格限制等,无法做绝大多数金融业务。业务生态的封闭性,通常会减缓行业进化的节奏;创新者本身不是用户,会降低创新效率和显著增加试错成本。
02
第二层,对金融行业的冲击
传统金融行业的资源本位逻辑(牌照、客户、渠道等)正遭遇AI的冲击。尤其今年DeepSeek爆火给各行各业的深远的影响,让越来越多的管理者认识到,专业能力(尤其是复杂问题解决与创造性洞见)超越资源禀赋,成为新的核心竞争力。相对传统金融业务的“资源型”人才,具备跨领域整合、算法思维与商业直觉的复合型个体的价值被急剧放大,也越来越受到社会的认可。
但金融行业的传统惯性与组织约束构成显著阻力:科层制架构下的流程固化、风险厌恶文化等,与新型AI复合人才的突破性思维,会在相当一段时间里不断冲突和调和。这种冲突本质上是工业时代 "标准化生产" 与数字时代 "个性化创造" 的范式对抗,其调和过程或将重塑金融行业的人才结构与协作模式,从依赖体系化资源转向激活个体创造力,从风险规避走向可控试错。
03
第三层,LLM对社会的冲击和“AI觉醒”
当 AI 生成内容成为信息传播的主流载体,一个 “算法闭环” 正在形成:AI 搜索依赖 AI 生成的结果,经过筛选与强化的 “标准文本”在输入输出循环中不断自我复制,最终可能导致特定领域的认知收敛:对于同一问题,世界可能趋向于唯一的“算法标准答案”。这种正反馈机制加速了信息的同质化,而 LLM 的快速迭代则将这一进程大幅提前。
相较于“AI 是否会觉醒”的技术焦虑,更值得警惕的是人类认知模式的退化:当决策越来越依赖算法推荐、思考被模型输出替代,人类的批判性思维与多元视角可能逐渐退化。这种“人类向 AI 的趋近”,是效率至上的逻辑下的主动选择,最终可能重塑全社会的认知体系:多样性与创造性消退,转向接受标准化与确定性。
引上,谈论 AI 是否会觉醒,不如担忧我们人类会不会越来像越像AI。
(第一篇完,系列第二篇将聚焦智能研发体系。)
附录:略,参见本期杂志。
本期更多内容
扫一扫订阅


金融研究与IT技术的密切结合和高度整合,是衡泰的特色之一。
衡泰研究中心拥有专业的定量分析研究团队,汇集多位华尔街专家及国内金融软件资深专家。研究领域覆盖定价模型、信用分析、风险计量、绩效分析、会计核算、市场规则、定量投资、机器学习等。
由衡泰研究出品的《投资管理》/ China JOIM ,旨在打造实证研究与实践的专业交流平台,搭建投资管理学术与业界的桥梁。