
摘 要
准确的风险预测是风险管理和投资组合优化的重中之重。判断协方差矩阵调整方法是否能够提高波动率预测的准确度,我们主要使用偏误统计量,即实际波动率和预测波动率的比值在一段时间区间内的标准差。基于此,我们完整地测试了多因子模型中的协方差矩阵的结构化调整,Newey-West 调整,特征值调整,贝叶斯压缩,和波动率偏误调整对风险预测的有效性。
相对于只看股票的历史收益率的简单模型,未经调整的多因子模型显著提高风险预测的准确度,预测更为稳健。在此之上,除波动率偏误调整外,其它四种协方差矩阵调整方法的偏误统计量更靠近1,说明这四种调整方法更进一步提高了风险预测的准确度。我们将使用更高频的方法对波动率偏误调整的有效性进行进一步的测试。后续我们将使用衡泰风险模型把组合风险拆分到因子层面,同时结合alpha预期收益率模型,构建最优投资组合。
全文8,496字,
预计阅读时间35分钟。
在多因子风险模型中,采用加权最小二乘回归法(WLS,Weighted Least Square)对个股收益率进行拟合后,得到因子收益率,从而计算股票收益率之间的协方差矩阵(RCM, Return Covariance Matrix) 和共同因子收益率协方差矩阵(FCM, Factor Covariance Matrix)为:
其中,V代表RCM,X为股票的因子暴露矩阵,F代表FCM,∆为股票特异性收益的方差矩阵(SRVM,Specific Return Variance Matrix)。
为了提高风险预测的准确度,我们需要对共同因子协方差矩阵F(方便起见,以下简称FCM1)和特异方差矩阵∆(以下简称FCM2)分别进行Newey-West调整,特征值调整,结构化调整,贝叶斯压缩,和波动率偏误调整。
判断协方差矩阵调整方法是否能够提高波动率预测的准确度,我们主要使用偏误统计量,即实际波动率和预测波动率的比值在一段时间区间内的标准差。我们称之为检验“大杀器”,因为这是检验一个调整方法是否有效的终极方法。偏误统计量检验将会放在各调整方法的研究之后,在报告的最后部分进行统一地检验。除此之外,对每种调整方法,都会有属于自己的独特的偏误统计量和其它方法来检验该调整是否有效。这些检验我们将会呈现在每个调整方法的结果里。总而言之,我们对协方差矩阵的调整结果进行多重检验,测试相应的调整方法是否有效,是否能提高预测准确度。
2.1 Newey-West调整
考虑到远期和近期对当前数据影响不同,我们通过半衰指数加权移动平均(Exponentially Weighted Moving Average,EWMA)计算日频的共同因子协方差矩阵
进而,考虑金融时序数据自相关性(autocorrelation),我们采取Newey-West调整。上面的协方差矩阵
因子收益率的时序相关性可以由滑动平均模型(Moving-Average Model, MA)描述,这但是此方法存在一个明显的缺点——调整后的协方差矩阵不一定满足半正定的要求。为了解决这一问题,Newey和West(1987)在调整过程中加入了Bartlett权重,提出了广泛使用的Newey-West调整方法:
Newey-West调整后的协方差矩阵是一个相合估计,并且满足半正定的要求。由于此因子收益协方差矩阵是基于日频数据计算得到,表征的是日度收益风险,因此,在用于月频调仓策略之前,我们还需要将此日频收益协方差矩阵频率转换至表征月度风险的月频收益协方差矩
这里,我们对因子收益协方差矩阵中非对角项和对角项的计算,前者滞后期D=2,后者滞后期D=5。
我们在进行协方差矩阵调整地实际操作过程中,发现单纯地按照Newey-West调整后的协方差矩阵并非半正定的(即分解出来的特征值有为负的值),针对于这个问题我们进行了深入的研究,最后解决了非半正定问题。
2.2 特征值调整
我们时常观察到投资组合的预测波动率与实际波动率偏差较大,往往表现为低估样本外低风险组合波动率,高估样本外高风险组合波动率(低估比高估会更加明显)。历史收益率数据本质上是真实收益率数据分布下的一次抽样,我们用历史收益率的协方差去估计组合的预期波动时,会产生抽样偏差,特征值调整(Eigenvector Adjustment)就是为了处理此问题。
Menchero、Wang和Orr(2012)发现,虽然真实的协方差矩阵是不可观测的,但是它与样本协方差之间的抽样误差却可以通过数值模拟得到,即给定真实的波动率(即预期波动率),统计模拟的样本协方差与预期波动率的偏差,并利用这种偏差对样本协方差进行调整,以得到真实协方差。
Menchero等发现,假设实际情形下样本协方差与真实波动率间的偏差,等于模拟出来的样本协方差与预期波动率间的偏差,那么特征组合的偏误统计量就会更加接近1,即波动率预测更加准确。基于此,我们可以通过数值模拟,即蒙特卡罗模拟,来计算这种偏差。
我们共进行1500次蒙特卡罗模拟,以获得对特征值偏误的稳定估计。每一次蒙特卡罗模拟,我们都假设收益率满足平稳性和正态性,但是实际收益率数据一般尖峰厚尾,不满足这两点假设,我们还需要额外的缩放,也就是对模拟统计出的偏差乘上一个系数
最后,为了完全消除特征组合的偏差,还需要两个额外的步骤。首先,我们用抛物线拟合每天的模拟波动率偏误得到拟合值。在估计拟合值时,我们将特征值最小的前8个特征组合的回归权重设为零,这样回归就可以忽略这8个特征组合的锯齿结构。
我们对调整系数
图1 不同
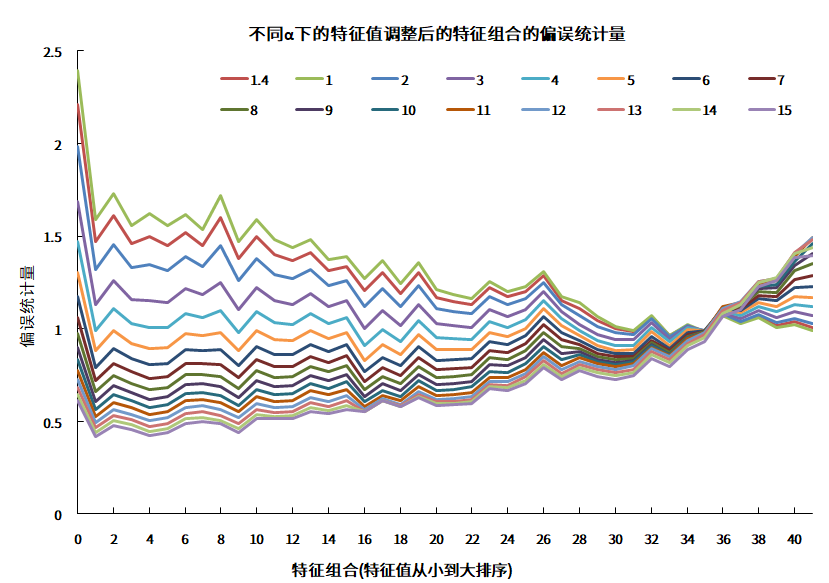
数据来源:衡泰一数通、财汇、衡泰研究部
衡泰多因子模型有42个因子,k∈[0,41]。不同α下的偏误统计量,与α呈现单调关系,和
case 1: 0≤k<29,α=4.5,k≥29,α=1
case 2: 0≤k<30,α=4.5,k≥30,α=1
case 3: 0≤k<29,α=4.5,k≥29,α=1.4
case 4: 0≤k<30,α=4.5,k≥30,α=1.4
结果如下图:
图2 四种cases的偏误统计量
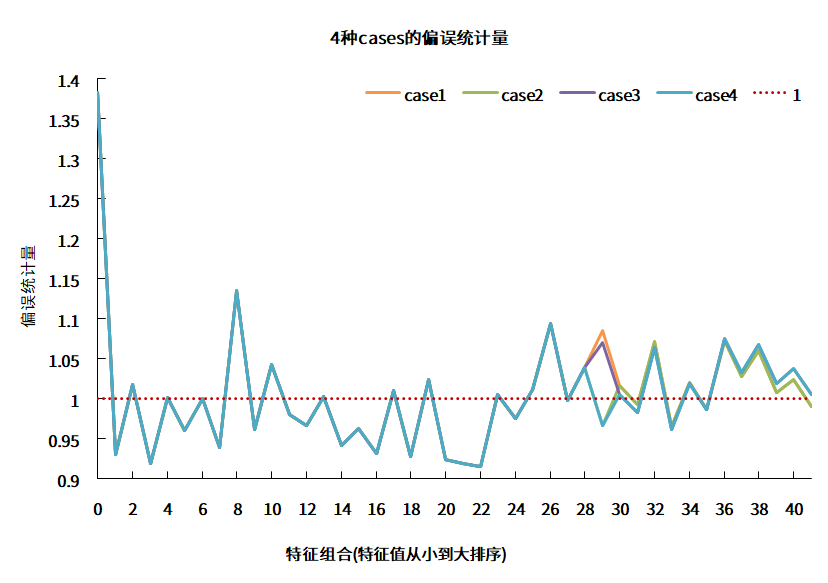
数据来源:衡泰一数通、财汇、衡泰研究部
从上图可以发现,case2的参数相对最好。所以,在衡泰多因子风险模型中,α分段取值,如下:
0≤k<30,α=4.5
30≤k,α=1
对比特征值调整前、后特征组合的偏误统计量,如下结果显示特征值调整能很好地修正低波特征组合的波动率被低估的问题。
图3 特征值调整前后偏误统计量的比较
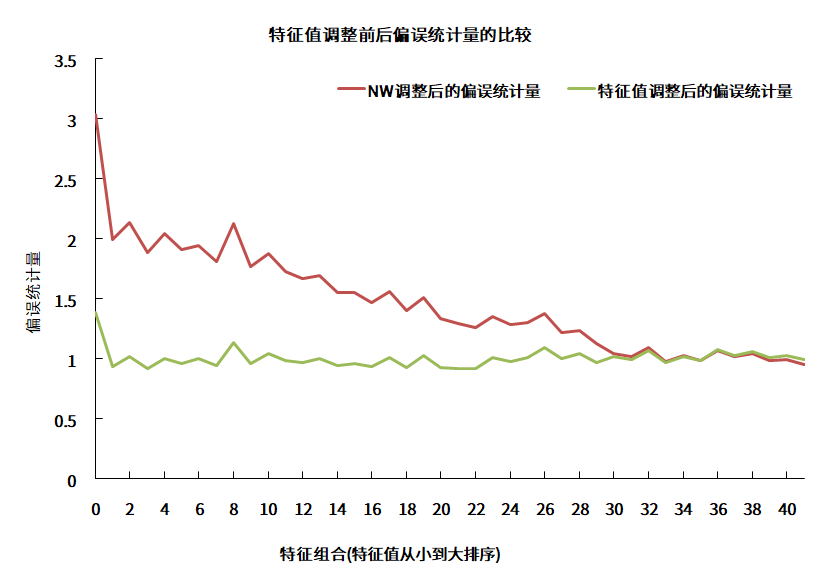
数据来源:衡泰一数通、财汇、衡泰研究部
一些关于特征值调整的研究显示低波特征组合的波动率被低估与因子收益率分布的肥尾现象相关。为了验证这一点,我们做了如下测试。假设因子收益率分布为正态分布(不同因子的方差相同和不同)和
图4 不同分布下的偏误统计量
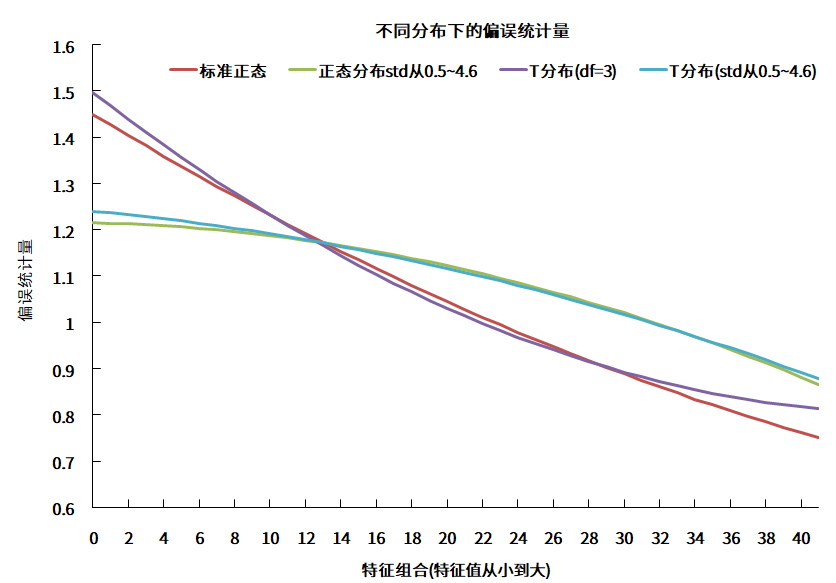
数据来源:衡泰一数通、财汇、衡泰研究部
2.3 波动率偏误调整
波动率偏误调整(Volatility Regime Adjustment)的目的是,利用一个时间段的偏误统计量,判断模型是否在某些时间系统性地高估或者低估了所有因子的收益风险。根据此波动率偏误将截面上的因子协方差矩阵进行整体缩放,从而提高协方差的反应速度。
定义第t个时间截面上,所有因子的总偏误统计量
由于单个截面数据容易受到随机噪声的影响,因此,我们对一段时期的总偏误统计量进行加权平均,得到因子波动率调整系数(Factor Volatility Multiplier)
最后,我们利用 对因子收益协方差矩阵进行调整:
为了检验波动率偏误调整效果,我们定义截面因子波动率
其中,
如果波动率偏误调整效果良好,在时间序列上,因子波动率调整系数
图5.因子波动率调整乘数λ与截面因子波动率CSV的关系
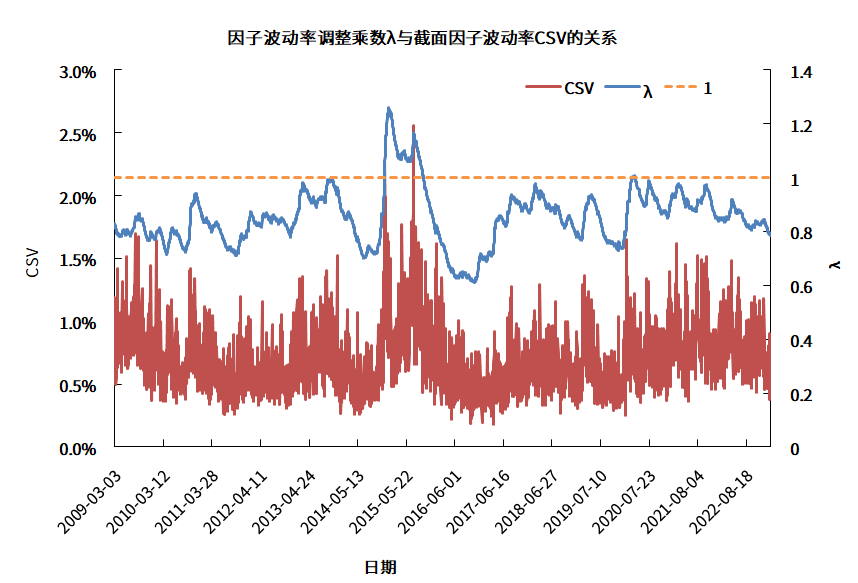
数据来源:衡泰一数通、财汇、衡泰研究部
下面对比了FCM1波动率偏误调整前、后因子偏误统计量
图6.FCM1波动率调整前后偏误统计量的252天滚动均值

数据来源:衡泰一数通、财汇、衡泰研究部
3.1结构化调整
结构化调整基本就是为了处理新股而量身定做的必不可少的方法论,也是FCM2调整的第一步。在实际市场中,新股上市、长期停牌的股票的特异风险数据可能存在一定的缺失。此外,若单个公司进行重大事件披露,将可能导致该股票的特异收益出现较大的异常值。结构化调整(Structural Adjustment)是假设具有相同特征的股票很有可能会具有相同的特异波动,根据此去修正特异收益缺失值和异常值对风险矩阵的影响。
其思想是,把全市场股票分为两个股票池,一个池子里是数据质量较好的股票,另外一个是数据质量较差的股票。对于数据质量较差的股票A而言,在数据质量较好的股票池中找到与该股票具有相似特征的股票B,并将A股票的特异风险向B股票的特异风险靠拢。
结构化调整的基本假设与多因子模型一脉相承——使用共同因子表征股票的风险特征,假设具有相同因子暴露的股票可能具有相同的特异性风险。结构化调整只针对存在明显缺失值或异常值,而数据质量较好的股票,结构化调整前、后的特异波动不变。
3.2 Newey-West调整
特异风险方差矩阵的Newey-West调整,相对于共同因子协方差矩阵的调整会简单些。因为我们假设单只股票的特异风险与共同因子之间互不相关,且不同股票之间的特异风险也彼此独立、互不相关,因此,特异风险方差矩阵是一个对角矩阵,即非对角线上元素均为0,只需要考虑对角线元素,且不涉及矩阵半正定问题。
与因子收益率协方差矩阵相同,由于日频特异性收益存在时序相关性,需要先通过Newey-West调整修正对特异性方差矩阵的估计,并将其频率调整至表征月度风险的月频特异性收益方差矩阵。
这里,滞后期D=5。
3.3 贝叶斯压缩调整
波动率具有连续性,历史是未来的最好预测。但是波动率也具有一定反转特性,即波动率较低的股票,很可能未来时刻波动率升高,同样地,波动率较高的股票,很可能未来波动率降低。
所以单只股票的特异风险不仅取决于自身,还取决于与它市值类似的股票特异风险的均值。因此,根据特异风险回归均值的趋势,我们还需要对特异收益方差矩阵进行贝叶斯压缩(Bayesian Shrinkage)调整,进一步修正风险预测值。其主要思想是将单只股票的特异风险向其所在的市值分组的市值加权平均风险进行压缩。
在每个时间截面上,我们将所有股票按照市值从小到大的顺序分为10组。注意的是,贝叶斯压缩调其实隐含了股票的特异风险与其市值不存在强关联的假定(允许弱关联),否则会出现悖论。如果特异风险和市值存在强关联,且股票波动率未来向分组的均值靠拢,那么分为10组和分为20组的结果会不一样,例如同一只股票,在分为20组时波动率被调小,在分为10组时,可能被调大了。
通过画出特异波动率和市值的对数的关系,可以明显看出市值和波动率有些单调性,但是很微弱,这说明贝叶斯压缩的逻辑是自洽的。
图7.特异波动率和市值的对数的关系
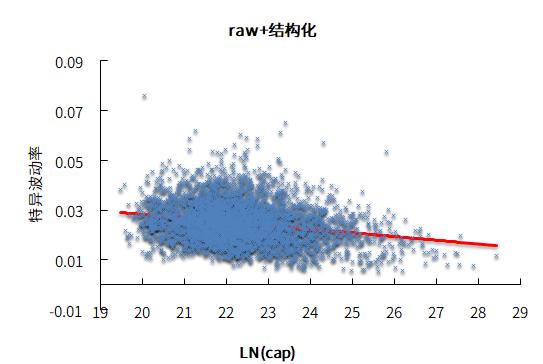
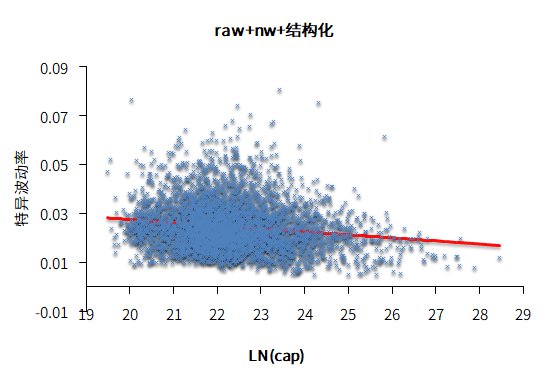
数据来源:衡泰一数通、财汇、衡泰研究部
上图中,横轴LN(cap)为市值的对数;纵轴代表的特异波动率;raw+结构化,代表特异波动率经过了结构化调整;raw+nw+结构化,代表着特异波动率是经过了NW调整和结构化调整。进一步,我们测试分10组和20组,组数不同会导致有多少只股票FCM2调整方向不一样。大约97%的调整是同向,从而进一步证明波动率和市值是弱关联,斜率可以认为是平的。
我们将所有股票,在每个时间横截面,按照贝叶斯压缩调整前后的波动率从小到大分成10组,计算各组内的标准化收益的标准差,即偏误统计量,然后再求各组的偏误统计量在整个区间的平均值。
下图为贝叶斯压缩调整前后偏误统计量的回测区间内的平均值,频率为月频,回测区间为2009年4月到2023年1月。
图8.FCM2贝叶斯调整前后偏误统计量均值(加权)
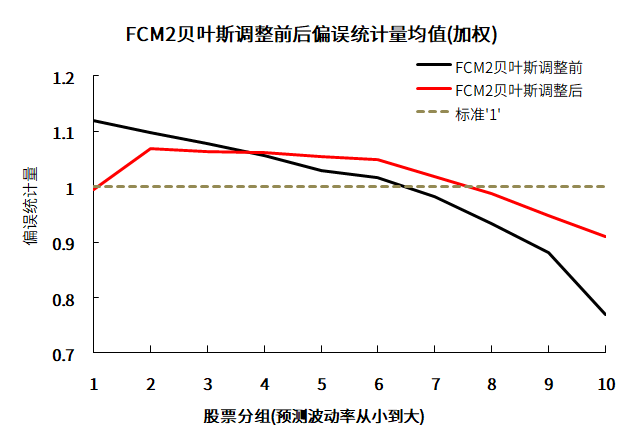
数据来源:衡泰一数通、财汇、衡泰研究部
由图可知,在进行贝叶斯压缩调整之前,即raw+结构化+NW调整(黑色),偏误统计量左边偏高,右边偏低,说明风险模型低估低波动率股票的风险(偏误统计量大于1),高估高波动率股票的风险(偏误统计量小于1)。贝叶斯压缩调整之后,即raw+结构+NW调整+贝叶斯压缩调整(红色),偏误统计量左边被压下去,右边被抬上来,更加靠近1,说明FCM2经过贝叶斯压缩调整后,进一步提高风险预测的准确性。
3.4 波动率偏误调整
在特异收益方差矩阵里,也需要进行波动率偏误调整(Volatility Regime Adjustment)。与因子收益协方差矩阵的调整思路一致,之前的调整步骤都是将每只股票视作独立的个体,并未考虑其他股票包含的信息。为了最大化利用可用信息,在这一步我们考虑同一时间截面上所有股票的特异波动,判断模型是否在某些时间段内系统性地高估或者低估了所有股票的特异性风险,并根据此波动率偏误对截面上的特异性收益方差矩阵进行整体缩放,从而提高协方差的反应速度。
定义在第t个时间截面上,所有股票特异风险的总偏误统计量
由于单个截面数据容易受到随机噪音的影响,因此,我们对一段时期的总偏误统计量进行加权平均,得到特异波动率调整系数
最后,我们利用 对特异波动进行调整:
为了检验特异风险经过波动率调整的结果,同样我们定义截面特异波动率:
如果波动率偏误调整效果良好,在时间序列上,特异波动率调整系数
图9.特异波动乘数λ与截面特异波动率CSV的关系
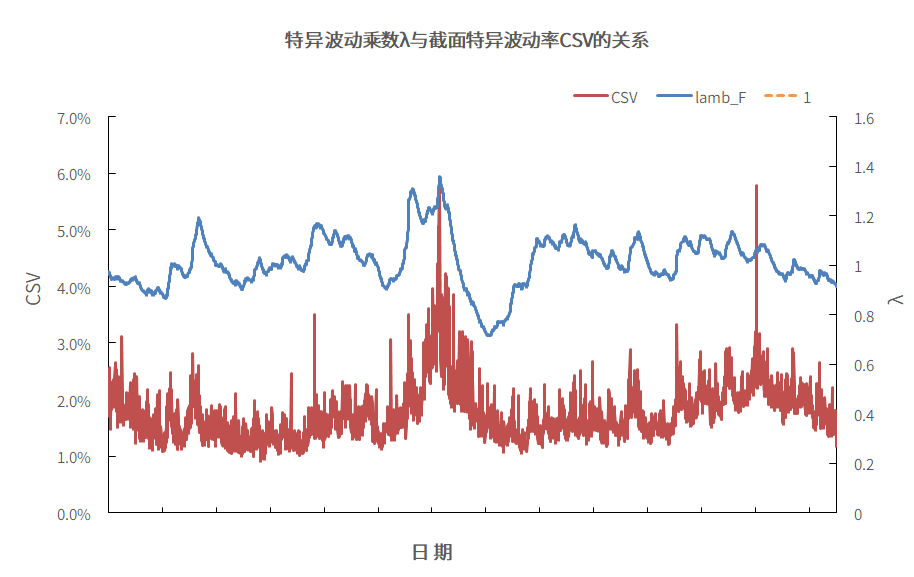
数据来源:衡泰一数通、财汇、衡泰研究部
在回测过程中,我们发现,截面特异波动率CSV会超过5%,10%甚至20%,非常不正常了,属于异常值。我们仔细核查数据,发现在这些日期,存在股票重组上市的情形(股票重组上市,上市首日不设涨跌幅),对我们的结果影响很大,对于这些股票的特异收益我们会进行缩尾处理(涨幅超过100%时,拉回到100%)。下图中,2015-07-09和2021-08-10日的CSV特别大是因为前者当天上证指数涨了5.76%,后者盐湖股份重组上市,上市当天涨了306%,即使缩尾,也是比较突出的值。
下图对比了FCM2波动率偏误调整前、后偏误统计量
图10.FCM2波动率调整前后偏误统计量的252天滚动均值
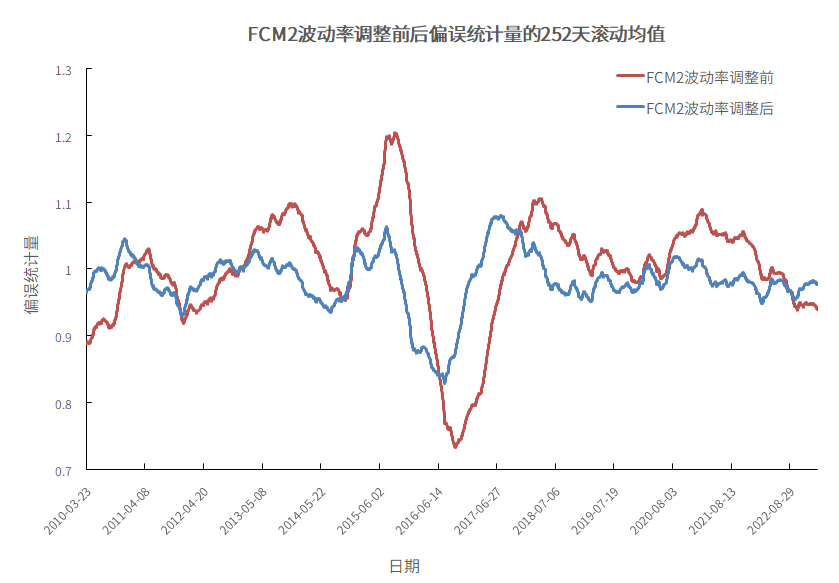
数据来源:衡泰一数通、财汇、衡泰研究部
4.1 “大杀器”的定义
关于所有的调整,我们有个统一的检验方法,简称为“大杀器”。首先,定义一下“大杀器”的偏误统计量。
假设
偏误统计量
其中,
偏误统计量衡量实际风险和预测风险之间的差异度。如果波动率预测是准确的,那么标准化收益
我们是在收益率服从正态分布的假设下,定义偏误统计量,然而现实中股票的收益率呈现出“尖峰厚尾”的形态,并不服从正态分布,那么95%置信区间会略微偏离上述值。
4.2 市场指数组合测试
我们使用各种不同的组合(沪深300,中证全指,中证1000和上证50)和当日FCM计算组合波动率,对下一个交易日的组合波动率进行预测,然后通过对FCM调整前后的滚动偏误统计量的比较,检验每一种调整方法对波动率预测的有效性,以决定是否采用调整方法和估计有效的模型参数。根据上文调整方法的检验效果,我们挑出三种FCM组合进行测试。
我们采用月频计算偏误统计量。首先,用日频数据在每个月底计算预测波动率,再乘以
表1.四种指数组合全程偏误统计量
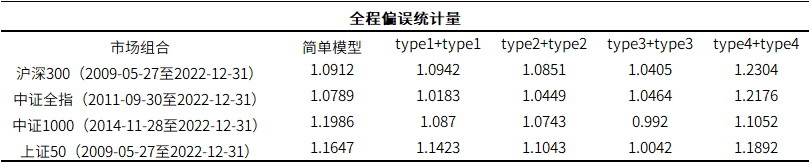
(注:各指数回测区间起始日不同是由于各指数发布时间不同。)
数据来源:衡泰一数通、财汇、衡泰研究部
其中,括号为各个市场组合测试区间,频率为月频。简单模型是指基于月收益率和历史波动率计算出的偏误统计量;对于FCM1,type1是raw,type2是raw+NW,type3是raw+NW+特征值,type4是raw+NW+特征值+波动率偏误;对于FCM2,type1是raw+结构化,type2是raw+NW+结构化,type3是raw+NW+结构化+贝叶斯,type4是raw+NW+结构化+贝叶斯+波动率偏误。上表里type1+type1的意思是FCM1为type1,同时FCM2为type1,诸如此类。
从上表可以看出,除了type4+type4,其他的偏误统计量比简单模型确实更靠近1,即风险预测比简单模型更有效,更加准确。具体地说,type1+type1到type2+type2到type3+type3,风险预测准确性逐步提高。到type4+type4波动率偏误调整方法的风险预测准确度反而有所下降。这符合逻辑。波动率偏误调整的调整方法是计算过去1年(252天)的波动率实际值和预测值的比值,求加权平均,当做调整系数,这样的调整方法的有效性存疑。虽然在月频大杀器的检验上,波动率偏误调整做比不做更差,后续我们将测试日频大杀器的检验,根据进一步的结果酌情考虑是否保留或剔除波动率偏误调整。
下图分别是沪深300指数、中证全指指数、中证1000指数、上证50指数成分股作为投资组合的偏误统计量12个月均值。
沪深300指数:回测区间是从2011-03到2022-12,频率为月频。
中证全指指数:回测区间是从2013-07到2022-12,频率为月频。
中证1000指数:回测区间是从2016-09到2022-12,频率为月频。
上证50指数:回测区间是从2011-03到2022-12,频率为月频。
从下面4张图可以看出来,不管是哪种调整方法,偏误统计量12个月均值波动都比简单模型要小。具体来说,type1+type1到type2+type2到type3+type3在简单模型偏误统计量非常远离置信区间时候,都能把偏误统计量往置信区间里拉,起到一定的调整作用。type4+type4的偏误统计量有的时间段会离其他的模型较远,但其偏误统计量12个月均值波动比较小,整体曲线更加平滑。
图11 沪深300指数
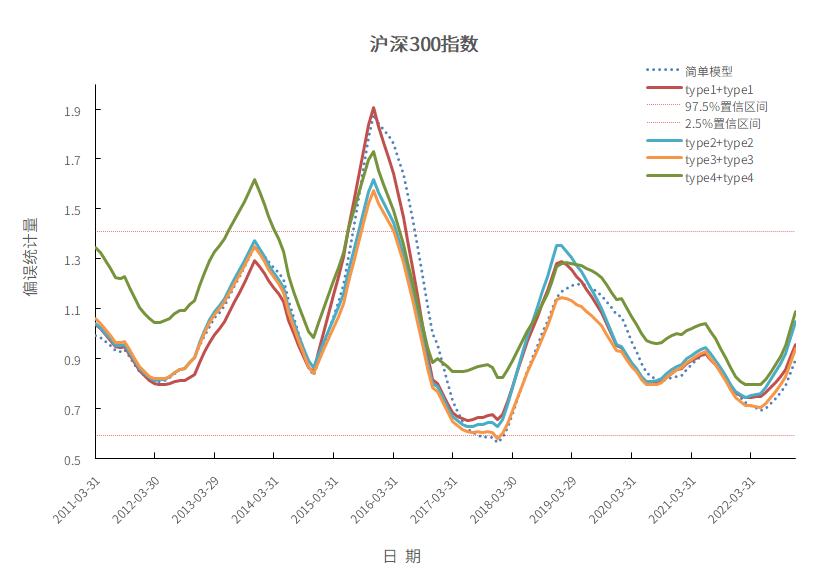
数据来源:衡泰一数通、财汇、衡泰研究部
图12 中证全指
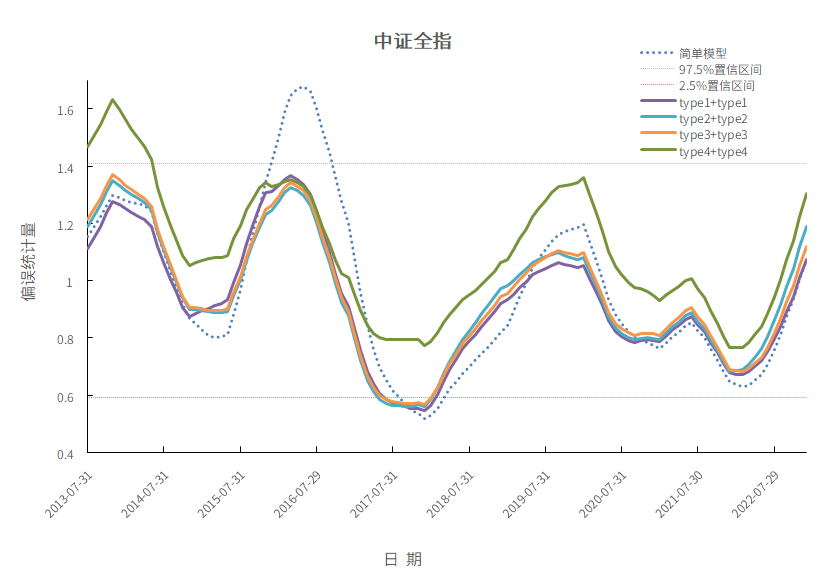
数据来源:衡泰一数通、财汇、衡泰研究部
图13 中证1000
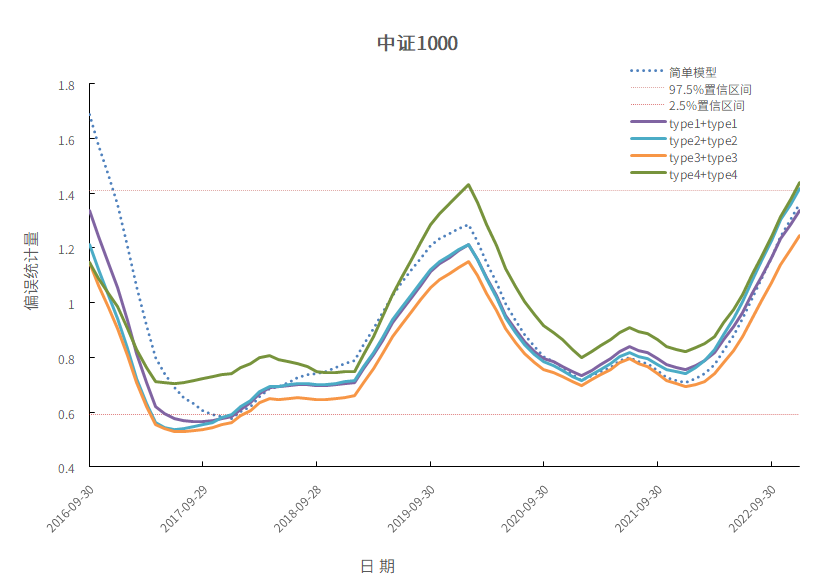
数据来源:衡泰一数通、财汇、衡泰研究部
图14 上证50指数
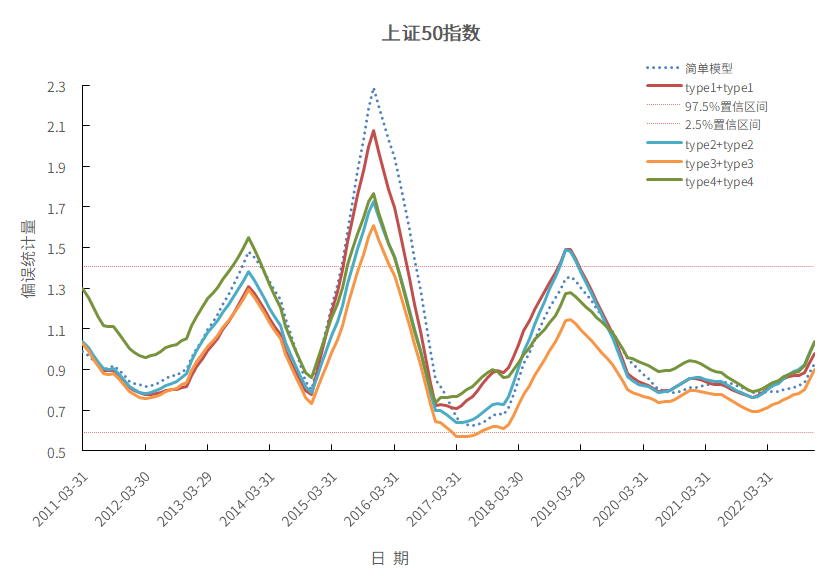
数据来源:衡泰一数通、财汇、衡泰研究部
如何理解在FCM1和FCM2协方差矩阵的调整时,波动率偏误调整好像有一定作用,但在组合层面,波动率偏误调整并没有起到作用?在协方差矩阵调整时定义的偏误统计量
我们完整地测试了多因子模型中的协方差矩阵的结构化调整,Newey-West 调整,特征值调整,贝叶斯压缩,和波动率偏误调整对风险预测的有效性。相对于只看股票的历史收益率的简单模型,未经调整的多因子模型显著提高风险预测的准确度,预测更为稳健。在此之上,除波动率偏误调整外,其它四种协方差矩阵调整方法的偏误统计量更靠近1,说明这四种调整方法更进一步提高风险预测的准确度。后续我们将对波动率偏误调整的有效性进行进一步的测试。
准确的风险预测是风险管理和投资组合优化的重中之重,后续我们将使用衡泰风险模型把组合风险拆分到因子层面,同时结合alpha预期收益率模型,构建最优投资组合。
作|者|介|绍

衡泰研究部Q
金融数学出身
主要从事多因子模型的研究和开发